문제점
나는 데이터 파싱하는 업무를 진행하고 있다.
그중 처음하는 경험이 있어서 기록한다.
자세히는 타겟은 C 구조체로 만들어져 있고 C로 부터 데이터를 송신하고 그것을 UDP 패킷으로 받아
JAVA에서 처리하는 것이다.
패킷의 rawdata만 보면 이렇게 생겼다.
0020 c1 01 70 10 00 76
0030 fd 1c 53 65 00 00 00 00 3f 00 00 00 03 01 00 00
0040 00 3f 00 1c 95 d5 7e 35 63 42 40 46 dc 3b d9 37
0050 b6 5f 40 cd cc cc cc cc 9c 7b 40 76 03 2f 40 b4
0060 93 b6 d2 be 6f 6e c0 00 8a 00 00 00 03 00 05 75
0070 56 43 bf 63 42 40 47 68 37 fd 34 b6 5f 40 00 00
0080 00 00 00 00 6d 40 81 e7 6a 3f a4 aa c0 fb 67 c4
0090 73 c0 00 86 00 00 00 05 00 4a c4 43 a8 39 63 42
00a0 40 1d a5 c3 bf 33 b6 5f 40 9a 99 99 99 99 a9 7b
00b0 40 b2 28 a6 3e 10 87 20 71 c5 9f 6a c0 00 00 00
00c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00e0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0100 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0110 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0120 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0140 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0150 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0160 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0170 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0180 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0190 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01e0 00 00 00 00 00 00 00 00 00 00 00MDD(메시지 정의서)가 존재하며 바이트 순서대로 파싱하면된다.
그러나 해석이 안된다.
왜?
위의 헥사를 -> (왼쪽에서 오른쪽) 순서대로 읽고 파싱했는데 이상한 결과들이 나오는 것이다.
메시지정의서
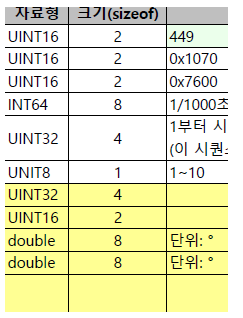
해결과정
위에 문제를 해결하기 위해서는 짚고 넘어가야 하는 개념이 있다.
- 리틀엔디안(Little Endian):
- 리틀엔디안은 낮은 주소부터 데이터의 낮은 바이트부터 메모리에 저장하는 방식입니다.
- 예를 들어, 32비트 정수
0x12345678이 있다면 메모리에는 다음과 같이 저장됩니다:78 56 34 12.
- 빅엔디안(Big Endian):
- 빅엔디안은 낮은 주소부터 데이터의 높은 바이트부터 메모리에 저장하는 방식입니다.
- 위의 예시인 32비트 정수
0x12345678이 빅엔디안으로 저장되면 메모리에는 다음과 같이 됩니다:12 34 56 78.
네트워크 패킷에서는 기본적으로 빅엔디안 사용하고
JAVA에서도 마찬가지로 빅엔디안 사용하며
C에서는 리틀엔디안을 사용한다.
데이터 송신자가 C 언어 이고
데이터 수신자가 JAVA 언어 일 경우
패킷을 제대로 해석하기 위해서는 어떠한 절차가 필요할까?
chat gpt 한테 물어보면 2가지의 방법을 알려준다.
방법1.
- C에서 송신할때, 빅엔디안으로 변환하여 보낸다.
#include <arpa/inet.h>
// ...
uint16_t data16 = htons(originalData16); // 16비트 데이터 빅엔디안 변환
uint32_t data32 = htonl(originalData32); // 32비트 데이터 빅엔디안 변환방법 2.
- JAVA에서 수신시, 리틀 엔디안으로 변환하여 수신한다.
// 예시: InputStream을 통한 데이터 수신
DataInputStream dis = new DataInputStream(socket.getInputStream());
int receivedData32 = Integer.reverseBytes(dis.readInt()); // 32비트 데이터 빅엔디안 변환
위의 방법을 다시 적용하고 파싱을 했고 잘 해결되었을까?
결론은 아니다.
타입 불일치 문제로 이상한 값들이 파싱되기 시작한 것이다.
예를 들어 C의 UINT16 타입은 JAVA에서 지원하지 않는 타입이다.
이런 타입 불일치는 또다른 문제를 야기시킨다.
간단하게 C에서는 8비트 정수를 나타내는 데이터 형식은 UINT8 로서 범위는 0~255이다.
JAVA에서는 byte 데이터 형식을 제공하며 범위는 -128~127 이다.
위의 경우 C에서는 128 이라는 값을 전송했지만
JAVA에서는 128은 지원하지 않는 범위므로 분명 이상한 값으로 인식한다.
부호가 없는 정수 기준으로 범위 보면 C가 JAVA보다 2배 더 큰 범위를 지원한다.
아래는 raw 패킷 데이터이다.

[-63, 1, 112, 16, 0, 118, 2, 29, 83, 101, 0, 0, 0, 0, 64, 0, 0, 0, 4, 1, 0, 0, 0, 64, 0, 66, 90, 67, -95, 58, 99, 66, 64, 73, -128, -37, 46, 52, -74, 95, 64, 102, 102, 102, 102, 102, -106, 123, 64, -12, 68, -58, 64, 78, 7, -73, -96, 125, -29, 66, -64, 0, -118, 0, 0, 0, 4, 0, 55, 20, 74, 84, -66, 99, 66, 64, 28, -107, 62, 114, 52, -74, 95, 64, -51, -52, -52, -52, -52, 12, 109, 64, -67, -84, 104, 63, -6, 43, 105, 54, +349 more]위의 메시지정의서를 토대로 byte 사이즈 대로 데이터를 자르면 -32570 과 같은 이상한 값이 해석된다.
이상하다? 메시지정의서를 토대로 확인하면 UINT16 는 음수값이 나올수가 없는데?
이는 C와 JAVA간의 타입 불일치 문제로 발생하는 것이다.
제대로 해석하기 위해선 중간에 변환이 필요하다.
C가 JAVA에 비해서 부호없는 정수 기준으로 2배 큰 범위기 때문에 JAVA byte 타입으로는 값을 배정할 수 없으니 int 값으로 배정한다.
...
int[] intData = new int[rawData.length];
for (int i=0; i<rawData.length; i++){
intData[i] = (rawData[i] & 0xff);
}
...
...
의문점
왜 intData[i] = (rawData[i] & 0xff); 할까?
정수 값을 byte로 변환하고 다시 정수로 변환하여 출력하면 맞지 않는 문제가 발생하기 때문에 & 0xff 연산을 해야한다.
자세한건 아래의 설명을 참고하자.
int a = 150; ---> a = 150(10) = 1001 0110(2)
byte b = (byte) a; ---> b = -106(10) = 1001 0110(2)
System.out.println(b); ---> b = -106(10)
System.out.println(b & 0xff); ---> 150출력
1001 0110 & 1111 1111 = 1001 0110
즉 byte형으로 강제 형변환한 b값은 출력시 -106이 나오지만
0xff와 비트연산후 출력시 기존의 150이 출력된다.tmi
0xff 는 `1111 1111(2) = 255(10)` 의미이다
이제 int 배열안에 있는 바이트 배열을 자바 타입에 맞게 적용시켜야 된다.
만약 그 요구 타입이 short 타입인 경우, 2바이트가 필요하기 때문에 아래처럼 쉬프트, | 연산을 통해 만들어준다.
1바이트는 8비트, 2바이트는 16비트 이기 때문에 왼쪽 시프트 연산으로 8비트만 이동한다면 16비트가 된다.
아래 처럼 적용한다.
System.out.println("packet size: " + (intData[1] << 8 | intData[0]));'나의 주니어 개발 일기 > 트러블슈팅' 카테고리의 다른 글
| [Troubleshoot] Next.js TTS 모바일 발음 이슈 및 Gemini API 서버 사이드 캐싱 해결기 (0) | 2026.02.03 |
|---|---|
| RabbitMQ 채널이 과도하게 생성되는 이슈 – Publisher만 사용했는데 Channel 51개 발생 (2) | 2025.07.22 |
| Spring Boot 쓰레드 풀 설정, 정말 안전할까? – 실무에서 놓치기 쉬운 포인트 (2) | 2025.05.30 |
| Spring Integration Udp 통신중 버퍼 크기로 인한 트러블 슈팅 (1) | 2024.07.05 |
| 코틀린 JPA 순환참조 문제 발생 (1) | 2024.01.30 |
