리액티브 프로그래밍 배경지식 알고가기
데이터 스트림과 변화에 반응하는 시스템을 구축하기 위한 프로그래밍 패러다임.
핵심은 '옵저버 패턴'과 '반응형 시스템'입니다. 옵저버 패턴을 통해 데이터 소스를 관찰하고, 데이터 변화 시 이를 구독하는 컴포넌트에 자동으로 알림을 보냅니다
왜 등장하게 되었을까?
기존 동기·블로킹 방식의 한계를 극복하기 위해 등장한 접근법
1.자원(스레드)의 한계
- 기존의 Java 웹 애플리케이션은 Thread-per-request 방식
- 스레드는 메모리와 CPU를 차지하는 무거운 자원
- 동시에 많은 요청을 처리하려면 수천 개의 스레드 필요 → 과부하 & 비효율
2.블로킹 I/O 문제
- 데이터베이스, 외부 API, 파일 시스템 등은 대부분 I/O 작업
- 일반적인 코드에서는 이런 I/O가 응답 올 때까지 스레드를 멈춤
- 스레드는 작업이 끝날때까지 놀면서 대기 = 낭비 심함
3.고성능/고동시성 시스템에 대한 요구 증가
- Netflix, Facebook, 카카오 등 트래픽 폭주 → 1초에 수만 건 요청 처리
- 기존 방식으론 하드웨어 확장 없이 감당이 어려움 → 스레드 효율적으로 쓰는 모델 필요
4.이벤트 기반 프로그래밍의 진화
- JavaScript의 이벤트 루프, Node.js 모델은 논블로킹 I/O 기반
- Java에도 이벤트 기반, 콜백 기반, 스트림 기반 모델이 도입됨 → 이 흐름 속에서 리액티브 프로그래밍이 등장
5.표준화의 필요: Reactive Streams
- 다양한 라이브러리(RxJava, Reactor 등)가 생겨났고 서로 호환이 안됨 →
Reactive Streams라는 표준 등장 - Java 9 이후에는
Flow API로 JDK에도 일부 포함됨
핵심 키워드 4가지
- 비동기(Asynchronous)
데이터나 이벤트가 발생할 때 처리됨(이벤트 기반으로 처리), 호출한 쪽은 결과를 기다리지 않고 다음 작업을 계속 수행 (Mono,Flux,Future,Callback,Promise)
- 논블로킹(Non-blocking)
작업이 I/O(예: DB, 네트워크) 등으로 대기하는 동안 스레드를 점유하지 않음, 자원을 효율적으로 사용 → 고성능/고동시성 가능
- 스트림 기반(Backpressure + Data Stream)
데이터가 스트림 형태로 흐르고, 이를 연산자 체인으로 처리, Backpressure로 소비자가 처리 가능한 만큼만 데이터를 요청할 수 있음
"데이터 흐름을 제어"하면서 시스템 과부하를 방지
- 선언형(Declarative)
map, flatMap, filter, zip, concat 등 연산자를 조합해 무엇을 할지 표현
가장 헷갈리는것?
동기,비동기,블로킹,논블로킹
동기/비동기는 요청한 작업에 대해 완료 여부를 신경 써서 작업을 순차적으로 수행할지 아닌지에 대한 관점이고,
블로킹/논블록킹은 단어 그대로 현재 작업이 block(차단, 대기) 되느냐 아니냐에 따라 다른 작업을 수행할 수 있는지에 대한 관점동기/비동기

비동기 성능 이점

자바스크립트 같은 경우 비동기로 작업을 요청하면 브라우저에 내장된 멀티 스레드로 이루어진 Web API에 작업이 인가되어 메인 Call Stack과 작업이 동시에 처리되게 된다동기,비동기는 작업 순서 처리 차이
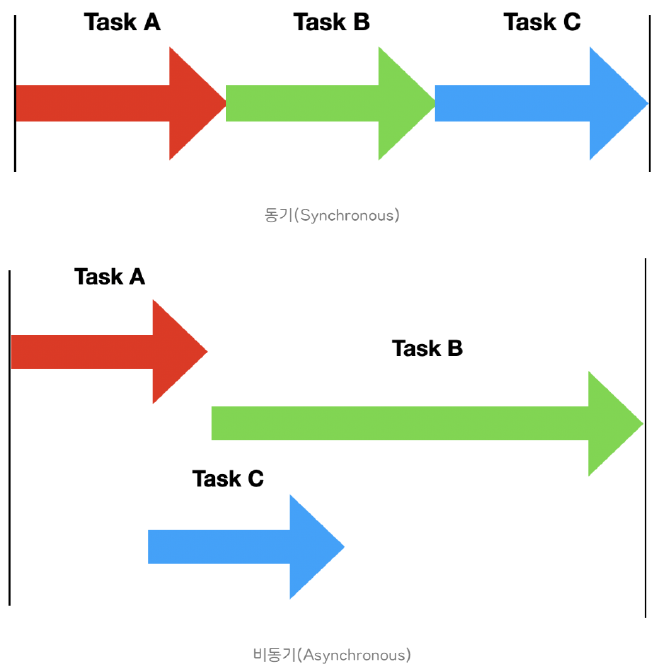
동기 작업은 요청한 작업에 대해 순서가 지켜지는 것을 말하는 것이고, 비동기 작업은 순서가 지켜지지 않을 수 있다는 것
블로킹/논블로킹
블로킹과 논블록킹은 단어에서 알 수 있듯이 다른 요청의 작업을 처리하기 위해 현재 작업을 block(차단, 대기) 하냐 안하냐의 유무를 나타내는 프로세스의 실행 방식
ex)파일을 읽는 작업이 있을 때, 블로킹 방식으로 읽으면 파일을 다 읽을 때까지 대기하고, 논블로킹 방식으로 읽으면 파일을 다 읽지 않아도 다른 작업을 할 수 있다.

Sync + Blocking 조합

예시 코드
javascriptconst fs = require('fs'); // 파일 시스템 모듈 불러오기
// 동기적으로 파일 읽기
const data1 = fs.readFileSync('file1.txt', 'utf8'); // file1을 sync으로 read 함
console.log(data1); // 파일 내용 출력하고 적절한 처리를 진행
const data2 = fs.readFileSync('file2.txt', 'utf8');
console.log(data2);
const data3 = fs.readFileSync('file3.txt', 'utf8');
console.log(data3);
Sync Blocking은 일반적으로 작업이 간단하거나 작업량이 적은 경우에 사용
작업량이 많거나 오래걸리는 경우는 worst, 이런 경우에는 Async Non-Blocking을 사용해야한다.
다른 그림

Application에서 I/O 요청을 한 후 완료되기 전까지는 Application이 Block이 되어 다른 작업을 수행할 수 없다. 이는 해당 자원이 효율적으로 사용되지 못하고 있음을 의미한다.
그러나 생각을 해보면 우리의 Application들은 Blocking 방식임에도 불구하고 마치 Block이 안된듯이 동작하는 것처럼 보인다. 이것은 우리가 Single Thread를 기반으로 하는 것이 아닌 Multi Thread를 기반으로 동작하기 때문이다.Multi Thread 기반이기 때문에 애플리케이션 전체가 블록되는 게 아니라 해당 요청을 처리하던 스레드만 Block되게 동작함으로써 Block의 문제를 해소하였다. 그러나 Thread 간의 전환(Context Switching)에 드는 비용이 존재하므로 여러 개의 I/O를 처리하기 위해 여러 개의 Thread를 사용하는 것은 비효율적으로 보인다.
*Context Switching
CPU 코어는 한 순간에 하나의 스레드만 실행, 그래서 OS는 짧은 시간 간격으로 스레드를 번갈아가며 실행
Async + NonBlocking 조합

예시 코드
// 비동기적으로 파일 읽기
const fs = require('fs'); // 파일 시스템 모듈 불러오기
fs.readFile('file.txt', 'utf8', (err, data) => { // 파일 읽기 요청과 콜백 함수 전달
if (err) throw err; // 에러 처리
console.log(data); // 파일 내용 출력
});
fs.readFile('file2.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
fs.readFile('file3.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
console.log('done'); // 작업 완료 메시지 출력*js 에서는 콜백함수를 통해 비동기 처리를 할 수 있다.
비동기 이기 때문에 작업의 순서를 고려하지 않아 동기 블로킹과는 거꾸로 가장 먼저 'done' 이라는 콘솔 로그가 찍히게 되고 그 후에 파일 내용이 출력될 것이다.
Async Non Blocking 조합은 작업량이 많거나 시간이 오래 걸리는 작업을 처리해야 하는 경우에 적합(대용량 처리)
다른 그림
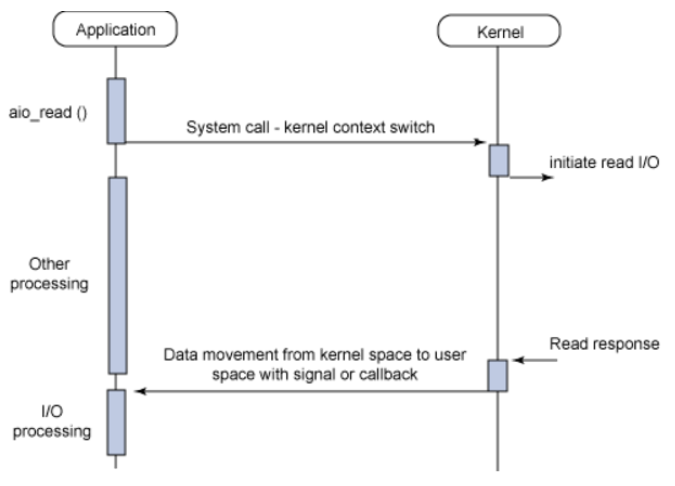
I/O 요청을 한 후 Non-Blocking I/O와 마찬가지고 즉시 리턴된다. 허나, 데이터 준비가 완료되면 이벤트가 발생하여 알려주거나, 미리 등록해놓은 callback을 통해서 이후 작업이 진행된다.
이전 두 I/O의 문제였던 Blocking이나 Polling이 없기 때문에 자원을 보다 더 효율적으로 사용할 수 있다.
활용 예시
웹 브라우저의 파일 다운로드가 비동기 논블로킹을 활용하는 예시 라고 할 수 있다.
웹 브라우저는 웹 사이트에서 파일을 다운로드할 때, 파일의 전송이 완료될 때까지 다른 작업을 하지 않고 기다리는 것이 아니라, 다른 탭이나 창을 열거나 웹 서핑을 할 수 있다. 이는 웹 브라우저가 파일 다운로드를 비동기적으로 처리하고, 콜백 함수를 통해 다운로드가 완료되면 알려주는 방식으로 구현되어 있기 때문이다.
Sync + Non Blocking 조합

다른 작업이 진행되는 동안에도 자신의 작업을 처리하고 (Non Blocking), 다른 작업의 결과를 바로 처리하여 작업을 순차대로 수행 하는 (Sync) 방식
예시 코드
// Runnable 인터페이스를 구현하는 클래스 정의
class MyTask implements Runnable {
@Override
public void run() {
// 비동기로 실행할 작업
System.out.println("Hello from a thread!");
}
}
public class Main {
public static void main(String[] args) {
// Thread 객체 생성
Thread thread = new Thread(new MyTask());
// 스레드 실행
thread.start();
// Non-Blocking이므로 다른 작업 계속 가능
System.out.println("Main thread is running...");
// Sync를 위해 스레드의 작업 완료 여부 확인
while (thread.isAlive()) {
System.out.println("Waiting for the thread to finish...");
}
System.out.println("Thread finished!");
System.out.println("Run the next tasks");
}
}
스레드(Thread) 객체를 만들어 요청 작업을 백그라운드에 돌게 하고 메인 메서드에서 while문을 통해 스레드가 모두 처리되었는지 끊임없이 확인하고, 처리가 완료되면 다음 메인 작업을 수행한다.
분명 스레드를 이용하여 작업을 병렬적으로 처리하도록 지시했지만, 메인 코드의 while문을 수행함으로서 요청한 작업의 완료 여부를 계속 확인하고 결과적으로 결국 동기적으로 작업을 순서대로 수행됨을 볼 수 있다.
다른그림
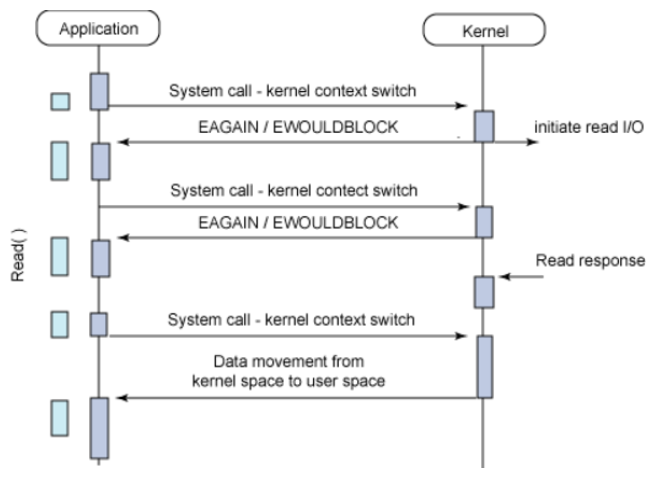
Application에서 I/O를 요청 후 바로 return되어 다른 작업을 수행하다가 특정 시간에 데이터가 준비가 다되었는지 상태를 확인한다. 데이터의 준비가 끝날 때까지 틈틈이 확인을 하다가 완료가 되었으면 종료된다.
여기서 주기적으로 체크하는 방식을 폴링(Polling) 이라고 한다. 그러나 이러한 방식은 작업이 완료되기 전까지 주기적으로 호출하기 때문에 불필요하게 자원을 사용하게 된다.
활용 예시1

동기 논블로킹은 흔하지 않는 케이스이지만 그래도 이를 표현할 수 있는 프로그램이 있다. 게임에서 맵을 이동할때이다.
우선 맵 데이터를 모두 다운로드 해야 할 것이다. 그동안 화면에는 로딩 스크린이 뜬다. 이 로딩 스크린은 로딩바가 채워지는 프로그램이 수행하고 있는 것이다. 즉, 제어권은 여전히 나한테 있어 화면에 로드율이 표시되는 것이다. 그리고 끊임없이 맵 데이터가 어느정도 로드가 됬는지 끊임없이 조회한다. 자신의 작업을 계속하고 있지만 다른 작업과의 동기를 위해 계속해서 다른 작업이 끝났는지 조회하는 것이다.
활용 예시2
파일을 다운로드 하면서 웹서핑을 하거나 유튜브 음악을 들을 수 있다
Async + Blocking 조합
다른 작업이 진행되는 동안 자신의 작업을 멈추고 기다리는 방식이다.
보통 Async-blocking은 개발자가 비동기 논블록킹으로 처리 하려다가 실수하는 경우에 발생하거나, 자기도 모르게 블로킹 작업을 실행하는 의도치 않은 경우에 사용된다. 때문에 이 방식을 안티 패턴이라고 치부하기도 한다.

Async + Blocking을 썼다면:
- 타임아웃 무조건 설정
- ThreadPoolExecutor 관리 철저히 (core/max size, queue, reject policy 등)
- 장기적으로는 non-blocking으로 전환 고려
활용 예제
Spring @Async + 블로킹 HTTP
@Async
public CompletableFuture<String> callExternalApi() {
// RestTemplate은 blocking I/O 방식
String response = restTemplate.getForObject("http://external.api", String.class);
return CompletableFuture.completedFuture(response);
}외부 API 호출은 블로킹 방식(RestTemplate), @Async로 별도 스레드에서 실행하므로 메인 스레드는 안 막힘, 결과는 Future/CompletableFuture로 비동기적으로 전달
호출자(메인 쓰레드)는 즉시 리턴 받음 (CompletableFuture)
하지만 내부에서 실제 작업은 blocking I/O 이므로, 스레드 하나는 HTTP 응답을 기다리며 대기 중
궁금증1
만약에 외부에서 우리 서버를 API 서버로 사용중이다.
우리의 API 서버는 로직을 비동기적으로 작성을해도 WAS가 tomcat(동기 was) 이라면?
Tomcat 요청 스레드와 @Async 스레드는 별도의 스레드이다. Spring단에서의 로직과 스레드적으로는 비동기적으로 동작할지라도 tomcat 단까지 확장해서 보게되면 Tomcat의 요청 스레드는 여전히 그 요청에 묶여 블로킹됨, 결국 웹 요청 처리 입장에선 동기적이다
Tomcat 요청 스레드 점유 문제는 비동기적 로직만으로는 해결이 안되며 어쩔 수 없이 WAS의 구조에 영향을 받는다.
완벽하게 비동기+논블로킹 구조를 적용하려면 WebClient + R2DBC + Reactive Stack(spring webflux, reactive programming)이어야 한다.
tomcat 8버전 이상에서는 논블로킹 I/O가 가능하다는데?
Tomcat 8 이상부터는 NIO (Non-blocking IO) 커넥터를 지원해서, 네트워크 입출력(소켓 레벨)에서는 논블로킹으로 동작 가능
그러나 tomcat이 애플리케이션 로직(서블릿 실행)을 처리하는 방식은, 기본적으로 요청 하나당 서블릿 컨테이너가 스레드 하나를 할당해서 처리(Thread-per-request 모델), 즉, 서블릿 호출 및 그 안의 비즈니스 로직(Spring MVC 컨트롤러, 서비스 등)은 블로킹 방식으로 처리됨
결과적으로는
tomcat 8버전 이상부터는 네트워크 I/O(요청 받기/응답 보내기) 부분은 논블로킹 처리 덕분에 많은 연결을 효율적으로 관리할 수 있지만
실제 애플리케이션 비즈니스 로직은 Thread-per-request 구조를 택하기 때문에 동기식 블로킹으로 동작함
tomcat 옛날 버전

tomcat 8버전 이상

Web Server(Tomcat)만 보면 논블로킹으로 동작하지만 Backend Server(Application) 단으로 가게되면 Spring mvc의 경우는 서블릿 스레드 풀(Thread per request) 구조를 따르기 때문에 결과적으로 애플리케이션 로직은 블로킹 처리
Thread per request Model


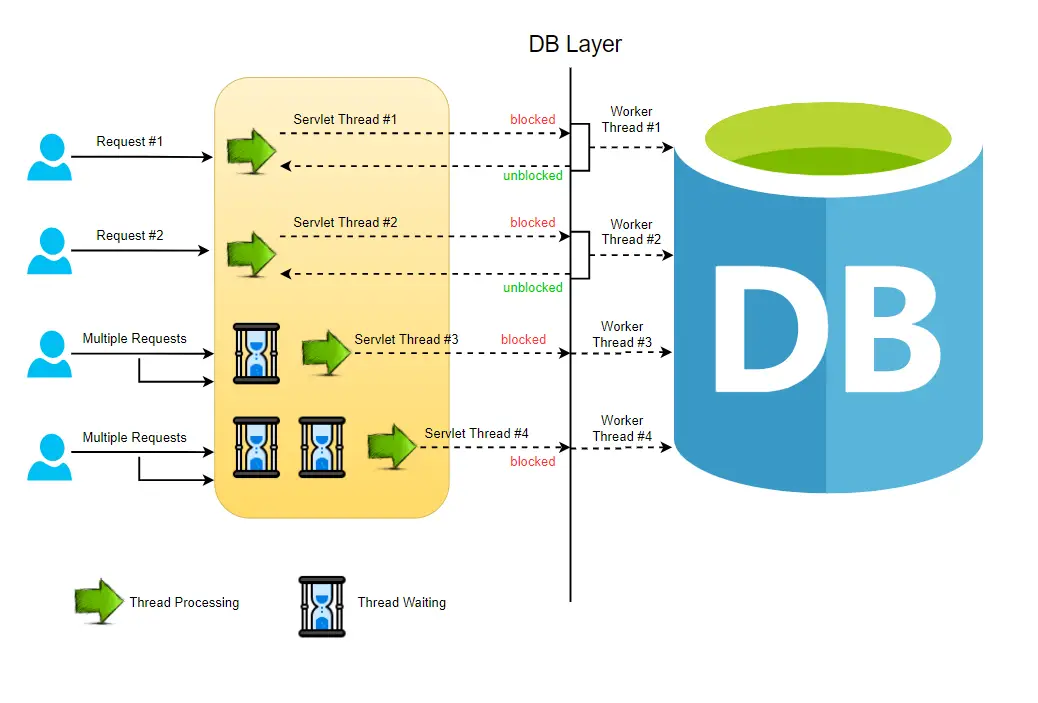
Tomcat 8부터는 네트워크 레벨 논블로킹 지원하는 것은 맞지만, 애플리케이션() 코드 실행 관점에서는 블로킹 방식이기 때문에 정확하게 이렇게 이해하는 게 좋음
궁금증2
tomcat 스레드 풀과 애플리케이션 스레드 풀은 서로 공유되어 쓰여지는 건가?
서로 다른 풀을 별도로 운영한다,
spring boot에서 내장톰켓 스레드 풀 구성 방법
server:
tomcat:
max-threads: 300
min-spare-threads: 10
accept-count: 100
connection-timeout: 10s애플리케이션(spring boot) 스레드 풀 구성 방법
@Bean(name = "taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // 기본 스레드 수
executor.setMaxPoolSize(50); // 최대 스레드 수
executor.setQueueCapacity(100); // 큐에 대기 가능한 작업 수
executor.setThreadNamePrefix("Async-"); // 디버깅용 이름
executor.initialize();
return executor;
}
궁금증3
내가 비동기 논블로킹으로 작성한다고 해도 os 커널 스레드 관점에서는?
애플리케이션 수준에서 비동기·논블로킹을 사용하더라도, OS 커널 수준에서는 여전히 스레드와 시스템 콜이 존재합니다.
OS에서는 이런 I/O 이벤트를 커널 스레드 or 이벤트 디멀티플렉서(epoll, kqueue, IOCP 등)를 통해 관리
어떻게 OS까지 하나하나 다 확인하냐..... 간단하게 확인할 수 있는 방법은?
내가 사용하는 라이브러리와 시스템 콜이 실제로 논블로킹인지 확인하는 것"
예: JDBC → 블로킹 / R2DBC → 논블로킹
Spring webflux(Noblocking Request Model)
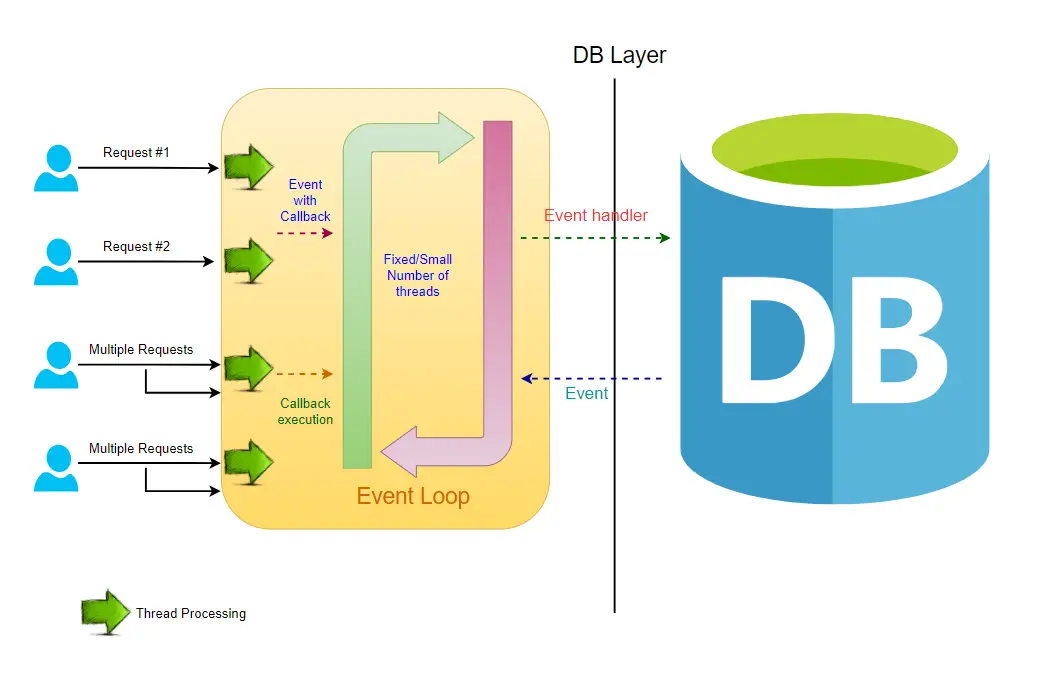

- [Event Queue]: 처리할 이벤트(예: 파일 읽기 완료, 네트워크 응답 등)가 쌓여있는 큐입니다.(내부적으로는
Selector가 감시하고,Channel에 등록된 이벤트들이 큐에 쌓임)
*Selector: channel을 감시하는 객체(Event Loop 쓰레드로 동작)
- [Process Events] 이벤트 루프(Event Loop)는 이벤트 큐에서 이벤트를 하나씩 가져와 처리
- [Event Loop] 이 루프는 이벤트 큐를 모니터링하면서 이벤트가 발생하면 해당 콜백 함수를 실행합니다.
- [Register Callback] 작업을 처리하기 위한 콜백 함수를 등록 (Mono.defer
,flatMap,map,subscribe) - [Intensive Operation(Platform)] 블로킹 I/O 작업이 발생하면, Event Loop는 해당 작업을 처리하기 위한 새로운 스레드를 생성
- [Operation Completion] 블로킹 I/O 작업이 완료되면, 결과를 Event Loop에게 알리고 새로운 스레드는 종료,(외부 작업이 완료되면 콜백을 통해 결과가 Reactor 체인으로 다시 전달됨)
- [Trigger Callback] Event Loop는 결과를 처리하고, 다른 작업을 처리 한다.(Netty의 이벤트 루프 쓰레드가 콜백을 실행하면서, Reactor 체인의 다음 단계를 실행)
결국 Noblocking Request Model은 Thread per request Model에 비해서 비교적 적은 스레드로 많은 부하를 처리할 수 있다.
참고자료:
https://www.codingshuttle.com/spring-boot-handbook/tomcat-server-threading-model/
https://medium.com/walmartglobaltech/thread-per-request-vs-7bf1f22f590
https://reflectoring.io/getting-started-with-spring-webflux/
'SPRING > 리액티브 프로그래밍' 카테고리의 다른 글
| Spring WebFlux 문법 정리 – Mono, Flux 사용법과 기본 예제들 (6) | 2025.08.08 |
|---|---|
| 리액티브 프로그래밍 개념정리(2) (0) | 2024.05.10 |
| 리액티브 프로그래밍 개념정리(1) (0) | 2024.05.09 |
