DB 이중화와 MySQL Replication 구조 정리
서비스를 운영하다 보면 애플리케이션 서버보다 더 조심스럽게 다뤄야 하는 영역이 있다.
바로 DB 서버다.
애플리케이션 서버는 여러 대로 늘리기 쉽고, 장애가 발생해도 다른 인스턴스로 트래픽을 우회하기 relatively 쉽다.
하지만 DB는 다르다.
DB에는 서비스의 상태와 데이터가 저장된다.
따라서 DB 장애는 단순한 서버 장애가 아니라 서비스 중단, 데이터 유실, 정합성 문제로 이어질 수 있다.
이 글에서는 DB 이중화가 왜 필요한지, MySQL 환경에서 어떤 방식으로 이중화를 구성할 수 있는지, 그리고 MMM, MHA, Group Replication 같은 방식이 어떤 차이를 가지는지 정리한다.
1. DB 이중화가 필요한 이유
DB 이중화의 핵심 목적은 장애 시간을 줄이는 것이다.
단일 DB 서버만 사용하는 구조에서는 DB 서버 장애가 곧 서비스 장애로 이어진다.
Application
|
DB 1대이 경우 장애 시간은 다음과 같다.
장애 시간 = DB 서버를 복구하는 데 걸리는 시간DB 서버가 재기동되거나, 디스크 장애가 복구되거나, 백업으로부터 복원될 때까지 서비스는 정상적으로 동작하기 어렵다.
2. DB 서버를 2대 둔다고 이중화가 되는 것은 아니다
DB 서버를 2대 준비했다고 해서 자동으로 이중화가 되는 것은 아니다.
예를 들어 다음과 같이 Master와 Slave 서버가 있다고 하자.
Master DB : 192.168.0.100
Slave DB : 192.168.0.200애플리케이션이 Master DB를 바라보고 있다가 Master에 장애가 발생하면, 운영자가 직접 애플리케이션 설정을 변경하여 Slave를 바라보게 할 수 있다.
장애 발생 전
Application -> 192.168.0.100
장애 발생 후
Application -> 192.168.0.200이 방식은 단일 DB보다 낫지만 여전히 수동 작업이 필요하다.
장애 시간 = 장애 감지 시간 + 설정 변경 시간 + 애플리케이션 재연결 시간운영자가 장애를 인지하고, 설정을 수정하고, 애플리케이션 커넥션을 재연결해야 한다.
즉, DB 서버는 2대지만 고가용성 구성이라고 보기는 어렵다.
3. VIP를 사용하면 장애 시간을 줄일 수 있다
이 문제를 줄이기 위해 VIP, 즉 Virtual IP를 사용할 수 있다.
VIP : 192.168.0.300
Master DB : 192.168.0.100
Slave DB : 192.168.0.200애플리케이션은 실제 DB 서버 IP가 아니라 VIP로 접속한다.
Application -> VIP -> Master DBMaster 장애가 발생하면 VIP를 Slave 쪽으로 이동시킨다.
장애 발생 전
VIP -> Master DB
장애 발생 후
VIP -> Slave DB이렇게 하면 애플리케이션의 DB 접속 정보는 변경하지 않아도 된다.
애플리케이션은 계속 동일한 VIP로 접속하고, 내부적으로 VIP가 가리키는 DB 서버만 바뀐다.
장애 시간 = 장애 감지 시간 + VIP 전환 시간 + 애플리케이션 reconnect 시간여기에 장애 감지와 Failover 작업까지 자동화하면 장애 시간을 더 줄일 수 있다.
4. DB 이중화에서 중요한 요소
DB 이중화는 단순히 DB 서버를 여러 대 두는 것이 아니다.
실제로는 다음 요소가 함께 고려되어야 한다.
| 요소 | 설명 |
|---|---|
| 데이터 복제 | Master의 데이터를 Standby 또는 Slave에 전달 |
| 장애 감지 | Master 장애 여부를 주기적으로 확인 |
| Failover | 장애 발생 시 Standby 또는 Slave를 새 Master로 승격 |
| VIP 또는 Proxy 전환 | 애플리케이션이 새 Master로 접속하도록 라우팅 변경 |
| 복제 재구성 | 나머지 Slave들이 새 Master를 바라보도록 변경 |
| 데이터 정합성 확인 | 장애 시점의 데이터 유실 또는 충돌 여부 확인 |
| 기존 Master 복구 처리 | 장애가 복구된 서버를 다시 클러스터에 편입 |
즉, DB 이중화는 복제 + 장애 감지 + Failover + 접속 전환 + 복제 재구성까지 포함하는 개념이다.
5. DB 이중화 방식
DB 이중화 방식은 크게 세 가지로 나눌 수 있다.
- Hardware 기반 이중화
- Disk 복제 기반 이중화
- DB Replication 기반 이중화
5-1. Hardware 기반 이중화
Hardware 기반 이중화는 공유 스토리지를 두고 Active 서버와 Standby 서버를 구성하는 방식이다.
Shared Disk
/ \
Active DB Standby DB평상시에는 Active DB만 서비스를 처리한다.
Standby DB는 대기 상태로 있다가 Active DB 장애 시 서비스를 넘겨받는다.
장점
- 구조가 비교적 명확하다.
- Active 서버 장애 시 Standby 서버로 전환할 수 있다.
- DB 자체 복제보다는 스토리지 중심으로 구성할 수 있다.
단점
- RHCS 같은 OS Cluster 솔루션이 필요할 수 있다.
- 고비용의 Shared Disk 구성이 필요하다.
- Standby 서버는 평상시에 거의 사용되지 않는다.
- Shared Disk 자체가 병목 또는 단일 장애 지점이 될 수 있다.
이 방식은 전통적인 온프레미스 환경에서 많이 사용되었지만, 비용과 운영 복잡도가 크다.
5-2. Disk 복제 기반 이중화
Disk 복제 방식은 Active 서버의 디스크 변경 내용을 Standby 서버로 복제하는 방식이다.
대표적으로 DRBD, Corosync, Pacemaker 조합을 사용할 수 있다.
Active DB Disk --network replication--> Standby DB DiskActive DB에서 데이터가 변경되면 네트워크를 통해 Standby 쪽 디스크로 복제된다.
장애가 발생하면 Pacemaker 같은 클러스터 관리 도구가 Standby를 Active로 승격시킨다.
장점
- Shared Disk 없이 구성할 수 있다.
- 별도의 고가 스토리지 없이 네트워크 기반 복제가 가능하다.
- 오픈소스 기반으로 구성할 수 있다.
단점
- 네트워크 latency에 영향을 받는다.
- Standby 서버는 평상시에 서비스 처리에 활용하기 어렵다.
- DB 레벨의 논리 복제가 아니라 디스크 블록 복제이므로 운영 시 주의가 필요하다.
- 장애 복구와 split-brain 방지를 위한 클러스터링 설계가 중요하다.
Hardware 기반 이중화와 Disk 복제 방식은 모두 Active-Standby 성격이 강하다.
즉, Standby 서버는 Failover 시점에만 본격적으로 사용된다.
5-3. MySQL Replication 기반 이중화
MySQL 환경에서는 DB 자체의 replication 기능을 이용해 이중화를 구성할 수 있다.
기본 구조는 다음과 같다.
Application
|
Master DB
|
Replication
|
Slave DBMaster에서 발생한 데이터 변경 사항을 Slave로 복제한다.
Slave는 평상시에 읽기 전용 서버로 활용할 수 있고, Master 장애 시 새 Master로 승격될 수 있다.
Replication 기반 이중화의 장점은 Standby 서버를 단순 대기 서버로만 두지 않고, 읽기 트래픽 분산에도 사용할 수 있다는 점이다.
6. MySQL Replication의 기본 동작
MySQL의 전통적인 복제는 Binary Log와 Relay Log를 기반으로 동작한다.
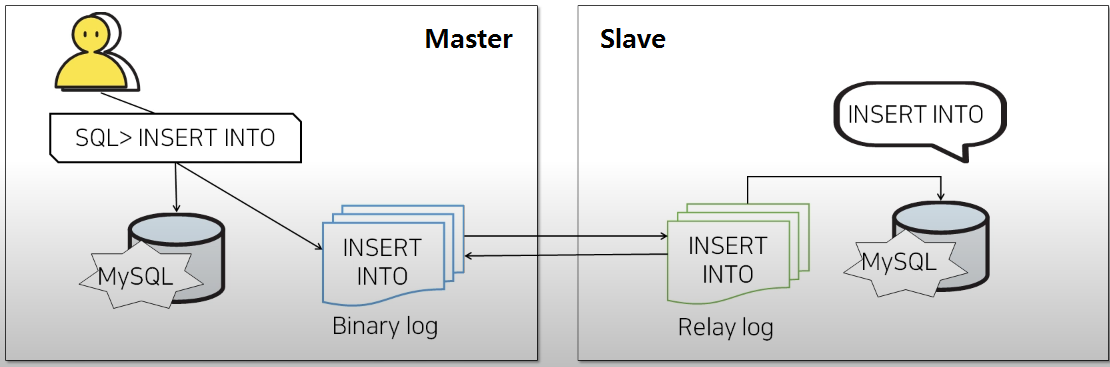
Binary Log
Binary Log는 Master DB에서 발생한 데이터 변경 이벤트를 기록하는 로그다.
예를 들어 다음과 같은 DDL, DML이 실행되면 Binary Log에 기록된다.
CREATE TABLE ...
DROP TABLE ...
INSERT ...
UPDATE ...
DELETE ...Relay Log
Relay Log는 Slave가 Master로부터 전달받은 Binary Log 이벤트를 로컬에 저장하는 로그다.
Slave의 SQL Thread는 Relay Log를 읽어서 자신의 DB에 변경 내용을 적용한다.
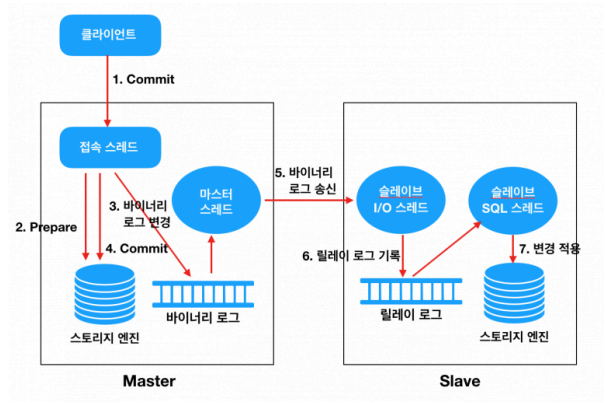
7. MySQL Replication 처리 흐름
전통적인 MySQL Replication 흐름은 다음과 같다.
1. Client가 Master에 INSERT / UPDATE / DELETE 요청
2. Master는 트랜잭션을 실행
3. 변경 이벤트를 Binary Log에 기록
4. Master는 Client에게 응답
5. Slave의 I/O Thread가 Master의 Binary Log 이벤트를 가져옴
6. Slave는 가져온 이벤트를 Relay Log에 기록
7. Slave의 SQL Thread가 Relay Log를 읽음
8. Slave DB에 변경 내용을 적용이를 그림으로 표현하면 다음과 같다.
Client
|
v
Master DB
|
| Binary Log
v
Slave I/O Thread
|
| Relay Log
v
Slave SQL Thread
|
v
Slave DB Apply중요한 점은 Master에서 commit이 완료된 시점과 Slave에 apply가 완료된 시점이 다를 수 있다는 것이다.
이 차이를 replication lag라고 한다.
8. MySQL 복제 방식의 종류

MySQL 복제 방식은 크게 다음과 같이 나눌 수 있다.
| 방식 | 설명 |
|---|---|
| Async Replication (default) | Master가 Slave 응답을 기다리지 않고 commit |
| Semi-sync Replication | 최소 1개 Slave가 이벤트를 받았다는 ACK를 받은 뒤 응답 |
| Group Replication | 그룹 내 노드들이 합의 과정을 거쳐 commit |
8-1. Async Replication(default)
Async Replication은 가장 기본적인 복제 방식이다.
Master commit 완료
-> Client 응답
-> 이후 Slave가 Binary Log를 가져가서 적용Master는 Slave가 이벤트를 받았는지, 적용했는지 기다리지 않는다.
장점
- 빠르다.
- 구조가 단순하다.
- Master의 쓰기 성능에 미치는 영향이 작다.
단점
- Master 장애 시 Slave에 전달되지 않은 데이터가 유실될 수 있다.
- replication lag가 발생할 수 있다.
Async Replication은 성능은 좋지만 장애 시점의 데이터 유실 가능성을 완전히 제거할 수 없다.
8-2. Semi-sync Replication
Semi-sync Replication은 Master가 최소 1개 Slave로부터 이벤트 수신 ACK를 받은 뒤 Client에게 응답하는 방식이다.
1. Master 트랜잭션 실행
2. Binary Log 기록
3. Slave가 이벤트를 수신
4. Slave가 ACK 응답
5. Master가 Client에게 성공 응답주의할 점은 Slave가 이벤트를 적용 완료했다는 의미가 아니라는 것이다.
대부분의 경우 Slave가 Relay Log에 이벤트를 수신했다는 수준의 보장에 가깝다.
장점
- Async보다 데이터 유실 가능성이 낮다.
- 최소 1개 Slave에는 변경 이벤트가 전달되었음을 기대할 수 있다.
- MHA 같은 HA 도구와 함께 사용하기 좋다.
단점
- Async보다 지연이 증가한다.
- Slave apply 완료를 보장하는 것은 아니다.
- 네트워크 지연이나 Slave 상태에 따라 Master 응답 시간이 영향을 받을 수 있다.
8-3. Group Replication
Group Replication은 전통적인 Master-Slave 복제와 다르게 여러 MySQL 서버가 하나의 그룹을 구성하고, Group Communication System을 통해 트랜잭션을 전파한다.
MySQL Node A
MySQL Node B
MySQL Node C트랜잭션은 commit 전에 그룹으로 전파되고, 각 노드는 충돌 여부를 검사한다.
과반수 이상의 노드가 승인하면 commit이 확정된다.
처리 흐름은 다음과 같다.
1. Client가 특정 노드에 트랜잭션 요청
2. 해당 노드는 commit 직전 pre-commit 상태로 대기
3. 트랜잭션 이벤트를 Group Communication System으로 전파
4. 각 노드가 certification 단계에서 충돌 여부 검사
5. 과반수 노드가 승인
6. 모든 노드가 동일한 순서로 commit
7. Client에게 응답Group Replication은 동기 복제에 가까운 강한 정합성을 제공하지만, 합의 과정이 있기 때문에 전통적인 Async Replication보다 latency가 증가할 수 있다.
9. MySQL 이중화 구성 방식
MySQL Replication을 기반으로 한 HA 구성 방식은 대표적으로 다음이 있다.
- MMM
- MHA
- MySQL Group Replication / InnoDB Cluster
- ProxySQL, HAProxy, MySQL Router 조합
- Cloud Managed DB
10. MMM
MMM은 Multi-Master Replication Manager의 약자다.
Perl 기반의 MySQL Auto Failover 오픈소스 도구다.
MMM은 DB 서버에 Agent를 실행하고, 별도의 Monitor가 Agent와 통신하면서 health check와 failover를 수행한다.
MMM Monitor
|
| health check / failover command
|
MMM Agent
|
MySQL Nodes10-1. MMM 기본 구조
MMM은 이름은 Multi-Master지만, 실무에서는 Active Master와 Passive Master를 두는 Active-Passive 구조로 운영되는 경우가 많다.
VIP
|
Active Master
<---->
Passive Master
Active Master와 Passive Master는 양방향 복제를 구성한다.
하지만 실제 write는 Active Master에서만 수행한다.
Passive Master는 데이터 변경이 발생하지 않도록 read-only 모드로 제어된다.
10-2. Slave를 추가한 MMM 구조
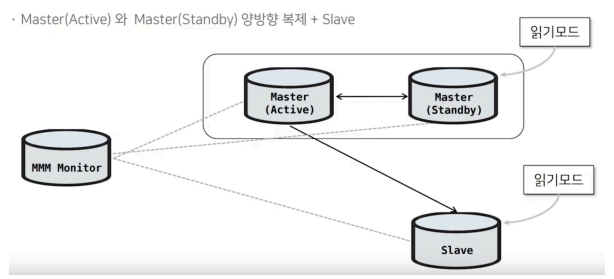
Slave를 추가하면 다음과 같은 구조가 된다.
Active Master
/ \
Passive Master Slave 1
Slave 2Active Master를 제외한 나머지 노드는 read-only로 운영된다.
Slave는 읽기 트래픽 분산 용도로 활용할 수 있다.
10-3. MMM Failover 과정
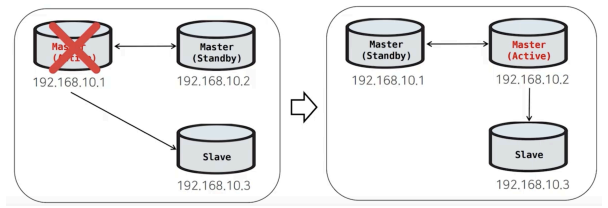
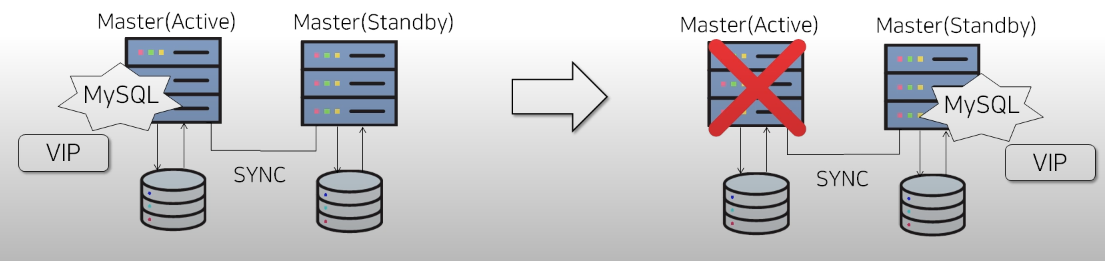
Active Master에 장애가 발생하면 MMM은 다음 절차를 수행한다.
1. Active Master 장애 감지
2. Active Master에서 VIP 회수 시도
3. Active Master를 read-only로 변경
4. 기존 세션 kill
5. Passive Master의 복제 상태 확인
6. Passive Master를 새 Active Master로 승격
7. Passive Master의 read-only 해제
8. VIP를 새 Active Master에 할당
9. Slave들이 새 Active Master를 바라보도록 복제 재구성이 과정을 통해 애플리케이션은 동일한 VIP로 DB에 재접속할 수 있다.
10-4. MMM의 한계
MMM의 가장 큰 한계는 split-brain과 데이터 충돌 가능성이다.
예를 들어 Active Master에서 다음 쿼리가 실행되었다고 하자.
INSERT INTO sample_table(id, name)
VALUES (101, 'B');이 이벤트가 일부 Slave에는 복제되었지만 Passive Master에는 아직 반영되지 않은 상태에서 Active Master가 장애가 발생할 수 있다.
이후 Passive Master가 새 Master로 승격되고 동일한 데이터가 다시 복제되거나 재처리되면, 이미 해당 데이터를 가지고 있던 Slave에서 PK 충돌이 발생할 수 있다.
Slave에는 id=101 존재
새 Master에는 id=101 없음
Failover 후 복제 재구성
Slave에서 PK 충돌 가능이러한 구조적 위험 때문에 MMM은 현재 신규 시스템에서는 거의 선택되지 않는다.
요즘은 MHA, Group Replication, InnoDB Cluster, ProxySQL 기반 HA 구성으로 대체되는 추세다.
MMM 장점
| 장점 | 설명 |
|---|---|
| VIP 기반 Failover | 애플리케이션 접속 정보를 단순화할 수 있음 |
| Active-Passive 구성 가능 | 쓰기 노드를 하나로 제한 가능 |
| Slave 읽기 분산 가능 | Slave를 read scale-out 용도로 활용 가능 |
MMM 단점
| 단점 | 설명 |
|---|---|
| 프로젝트 유지보수 중단 | 신규 도입에 적합하지 않음 |
| split-brain 위험 | 두 Master가 동시에 write 가능 |
| circular replication 복잡성 | 양방향 복제로 충돌 가능 |
| 데이터 정합성 리스크 | Failover 시점에 복제 차이 발생 가능 |
11. MHA
MHA는 Master High Availability의 약자다.
MySQL Replication 환경에서 Master 장애를 감지하고 자동 Failover를 수행하는 오픈소스 도구다.
MMM과 달리 MHA는 기본적으로 Single Master 구조를 전제로 한다.
Master
/ \
Slave 1 Slave 2Master 장애 시 Slave 중 하나를 새로운 Master로 승격하고, 나머지 Slave들이 새 Master를 바라보도록 복제를 재구성한다.
11-1. MHA 구성
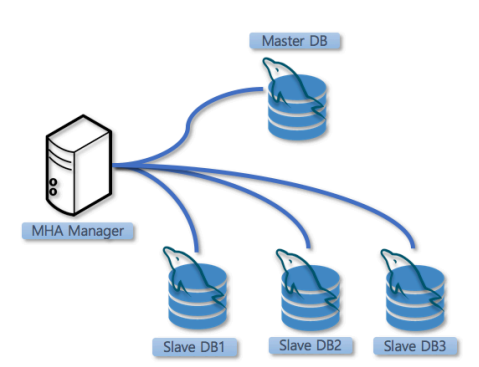
MHA는 일반적으로 다음 구성 요소를 가진다.
| 구성 요소 | 설명 |
|---|---|
| MHA Manager | 장애 감지 및 Failover 수행 |
| Master DB | 현재 쓰기 담당 DB |
| Slave DB | 복제 대상 DB, 장애 시 승격 후보 |
| VIP Script | Failover 시 VIP 전환 처리 |
| SSH | 각 노드에 접속하여 로그 수집 및 명령 수행 |
MHA는 Agentless 방식에 가깝다.
MHA Manager가 SSH를 통해 각 DB 서버에 접근하여 상태를 확인하고 필요한 작업을 수행한다.
11-2. MHA 장애 감지
MHA Manager는 주기적으로 Master DB에 접속하여 상태를 확인한다.
일반적으로 다음과 같은 방식으로 장애 여부를 판단한다.
CONNECT 체크
SELECT 체크
INSERT 체크여러 번 실패하면 Master 장애로 판단하고 Failover를 수행한다.
11-3. MHA Failover 과정
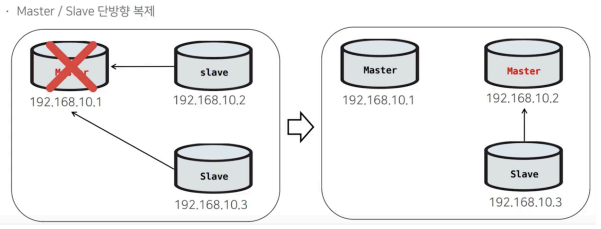
MHA의 Failover는 다음 순서로 진행된다.
1. Master 장애 감지
2. Slave 중 가장 최신 데이터를 가진 노드 탐색
3. 장애 Master에서 가능한 Binary Log 수집 시도
4. 각 Slave의 Relay Log 차이 비교
5. 가장 최신 Slave를 새 Master로 승격
6. 부족한 Relay Log 이벤트를 다른 Slave에 적용
7. 나머지 Slave들이 새 Master를 바라보도록 복제 재구성
8. VIP를 새 Master로 이동MHA의 중요한 특징은 장애 시점에 Slave들 간의 relay log 차이를 비교하여 데이터 손실을 최소화하려고 한다는 점이다.
즉, 단순히 특정 Slave를 고정적으로 승격시키는 것이 아니라, 가장 최신 데이터를 가진 Slave를 찾아 Master로 승격한다.
11-4. MHA의 장점
| 장점 | 설명 |
|---|---|
| Single Master 구조 | MMM보다 데이터 충돌 가능성이 낮음 |
| 자동 Failover | Master 장애 시 Slave 승격 자동화 가능 |
| 데이터 손실 최소화 | Binary Log, Relay Log를 이용해 차이 보정 |
| 기존 Replication과 호환 | Async, Semi-sync Replication과 조합 가능 |
| 성숙한 운영 사례 | 전통적인 온프레미스 MySQL 환경에서 많이 사용됨 |
11-5. MHA의 단점
| 단점 | 설명 |
|---|---|
| Write 중단 시간 존재 | Slave 승격 중 쓰기 요청은 일시 중단 |
| 구성 복잡도 | Manager, SSH, VIP script 등 운영 요소 필요 |
| 장애 복구 후 재편입 필요 | 기존 Master 복구 후 자동 재참여가 어렵다 |
| 추가 도구 의존 | MySQL 자체 내장 HA 기능은 아님 |
| 프로젝트 노후화 | 최신 신규 구성에서는 대체 솔루션을 검토하는 경우가 많음 |
MHA는 Failover 시간을 줄일 수 있지만, 장애 발생부터 새 Master 승격까지 수 초에서 수십 초의 write 중단 시간이 발생할 수 있다.
Read 요청은 Slave를 통해 어느 정도 유지할 수 있지만, Write 요청은 새 Master 승격이 완료될 때까지 정상 처리되기 어렵다.
12. MySQL Group Replication
MHA가 기존 MySQL Replication 구조 위에서 Failover를 자동화하는 방식이라면, Group Replication은 MySQL 자체에서 제공하는 클러스터 기반 복제 방식이다.
Group Replication에서는 여러 MySQL 서버가 하나의 그룹을 형성한다.
MySQL Node A
MySQL Node B
MySQL Node C각 노드는 Group Communication System을 통해 트랜잭션을 공유하고, certification 단계를 통해 충돌 여부를 검사한다.
12-1. Single-primary 모드
Single-primary 모드에서는 하나의 노드만 write를 처리한다.
Primary Node : Read / Write
Secondary Node : Read Only
Secondary Node : Read OnlyPrimary 노드 장애 시 나머지 노드 중 하나가 자동으로 새 Primary로 선출된다.
이 방식은 기존 Master-Slave 구조와 유사하게 이해할 수 있지만, 내부적으로는 그룹 합의와 충돌 검사를 사용한다.
12-2. Multi-primary 모드
Multi-primary 모드에서는 모든 노드가 write를 받을 수 있다.
Node A : Read / Write
Node B : Read / Write
Node C : Read / Write하지만 모든 노드에서 동시에 write가 가능하다는 것은 그만큼 충돌 가능성도 존재한다는 뜻이다.
예를 들어 서로 다른 노드에서 같은 row를 동시에 update하면 certification 단계에서 충돌이 발생할 수 있다.
이 경우 하나의 트랜잭션은 rollback될 수 있고, 애플리케이션에서는 재시도 로직이 필요하다.
실무에서는 정합성과 운영 안정성을 위해 Single-primary 모드를 더 선호하는 경우가 많다.
12-3. Group Replication의 장애 처리
Group Replication은 과반수 기반으로 그룹을 유지한다.
예를 들어 3대의 노드가 있다고 하자.
A <-> B <-> C이때 네트워크 문제로 A가 고립되면 다음과 같이 나뉠 수 있다.
A / B <-> CB와 C는 2대이므로 과반수를 확보한다.
따라서 그룹을 유지할 수 있다.
반면 A는 혼자이기 때문에 과반수를 확보하지 못한다.
이 경우 A는 정상적인 write 처리를 계속할 수 없고, read-only 상태로 전환되거나 그룹에서 제외될 수 있다.
이 방식은 split-brain을 막기 위해 필요하지만, 네트워크가 불안정한 환경에서는 가용 노드 수가 줄어드는 문제가 발생할 수 있다.
12-4. Group Replication의 장점
| 장점 | 설명 |
|---|---|
| MySQL 내장 기능 | 외부 HA 도구 의존도를 줄일 수 있음 |
| 자동 Primary 선출 | Single-primary 모드에서 장애 시 자동 승격 |
| 강한 정합성 | 과반수 합의와 certification 기반 |
| split-brain 방지 | 과반수 기반으로 그룹 유지 |
| InnoDB Cluster와 연계 | MySQL Router와 함께 공식 HA 구성이 가능 |
12-5. Group Replication의 단점
| 단점 | 설명 |
|---|---|
| latency 증가 | 합의 과정 때문에 Async보다 느릴 수 있음 |
| 네트워크 품질 중요 | 노드 간 지연, 패킷 손실에 민감 |
| 충돌 처리 필요 | Multi-primary 모드에서 rollback 가능 |
| 운영 복잡도 | MySQL Router, ProxySQL 등과 함께 설계 필요 |
| 쓰기 성능 제한 | 강한 정합성을 얻는 대신 성능 비용 발생 |
Group Replication은 정합성과 자동 Failover 측면에서는 강력하지만, 모든 환경에서 성능적으로 유리한 것은 아니다.
네트워크 품질이 좋고, 노드 간 latency가 낮은 환경에서 사용하는 것이 적합하다.
13. InnoDB Cluster
InnoDB Cluster는 MySQL Group Replication을 기반으로 하는 MySQL 공식 HA 구성이다.
일반적으로 다음 요소로 구성된다.
MySQL Server + Group Replication
MySQL Shell
MySQL Router애플리케이션은 MySQL Router를 통해 DB에 접속한다.
MySQL Router는 현재 Primary 노드를 알고 있으며, 장애 발생 시 새 Primary로 트래픽을 라우팅한다.
Application
|
MySQL Router
|
Group Replication ClusterInnoDB Cluster는 Group Replication을 직접 구성하는 것보다 관리 편의성이 좋다.
신규 MySQL HA 구성을 검토한다면 Group Replication 단독보다는 InnoDB Cluster 관점에서 보는 것이 더 현실적이다.
14. MHA와 Group Replication 비교
MHA와 Group Replication은 모두 MySQL HA를 위해 사용할 수 있지만 접근 방식이 다르다.
| 항목 | MHA | Group Replication / InnoDB Cluster |
|---|---|---|
| 기본 구조 | Master-Slave Replication 기반 | 그룹 합의 기반 |
| 복제 방식 | Async 또는 Semi-sync | Group Communication System |
| Failover | 외부 도구가 수행 | MySQL 그룹 내부에서 처리 |
| 데이터 손실 | 최소화 가능하지만 구성에 따라 유실 가능 | 과반수 합의 기반으로 더 강한 정합성 |
| Write 중단 | Failover 동안 발생 | Single-primary 전환 동안 짧게 발생 |
| 성능 | 상대적으로 빠름 | 합의 비용으로 latency 증가 |
| 운영 난이도 | 외부 도구, SSH, VIP script 필요 | Group Replication, Router 운영 필요 |
| 적합 환경 | 전통적인 온프레미스 MySQL | 신규 HA 구성, 공식 MySQL HA 방향 |
간단히 정리하면 다음과 같다.
기존 Master-Slave 구조를 유지하면서 Failover 자동화가 필요하다
-> MHA
신규로 MySQL HA 구성을 설계하고 공식 클러스터 방식을 사용하고 싶다
-> Group Replication / InnoDB Cluster15. 각 방식의 특성 요약
| 방식 | 일관성 | 가용성 | 성능 | 특징 |
|---|---|---|---|---|
| Async Replication | 낮음 | 높음 | 빠름 | 단순하지만 장애 시 유실 가능 |
| Semi-sync Replication | 중간 | 높음 | Async보다 약간 느림 | 최소 1개 Slave 수신 보장 |
| MMM | 낮음~중간 | 중간 | 빠름 | 현재 신규 도입 비추천 |
| MHA | 중간 | 중간~높음 | 빠름 | 전통적인 MySQL HA 방식 |
| Group Replication | 높음 | 높음 | 상대적으로 느림 | 합의 기반, MySQL 내장 |
| InnoDB Cluster | 높음 | 높음 | 상대적으로 느림 | 공식 MySQL HA 구성 |
| Galera Cluster | 높음 | 높음 | 상대적으로 느림 | 동기식 Multi-master 계열 |
| Cloud Managed DB | 높음 | 매우 높음 | 서비스별 최적화 | 운영 편의성 가장 높음 |
16. 실무 선택 기준
DB 이중화 방식을 선택할 때는 기술 자체보다 운영 환경과 요구사항을 먼저 봐야 한다.
16-1. 온프레미스 환경
온프레미스에서 직접 MySQL을 운영해야 한다면 다음 구성이 현실적이다.
MHA + Semi-sync Replication + VIP이 구성은 전통적인 MySQL Replication 환경과 호환성이 좋고, 장애 시 자동 Failover를 구성할 수 있다.
다만 기존 Master 장애 복구 후 재편입, 복제 재구성, VIP script 관리 등 운영 절차를 명확히 문서화해야 한다.
16-2. 신규 MySQL HA 구성
새로운 시스템에서 MySQL HA를 구성한다면 다음 구성을 검토할 수 있다.
InnoDB Cluster + MySQL Router이는 MySQL 공식 HA 구성에 가깝고, Group Replication을 기반으로 자동 Primary 선출과 라우팅을 제공한다.
다만 네트워크 latency, 노드 간 통신 안정성, write 성능 저하 가능성을 충분히 검증해야 한다.
16-3. 클라우드 환경
클라우드 환경이라면 직접 MMM, MHA, DRBD, Pacemaker를 구성하기보다 Managed DB를 우선 검토하는 것이 좋다.
예를 들면 다음과 같다.
AWS RDS / Aurora
Google Cloud SQL
Azure Database for MySQLManaged DB는 자동 백업, 장애 조치, 모니터링, 패치, 복제 구성을 상당 부분 제공한다.
직접 구축하는 것보다 비용이 높아 보일 수 있지만, 운영 인력 비용과 장애 대응 리스크까지 고려하면 실무적으로 더 합리적인 경우가 많다.
17. DB 이중화 도입 시 반드시 확인할 것
DB 이중화는 장애 시간을 줄이기 위한 기술이지만, 잘못 구성하면 오히려 장애 원인이 될 수 있다.
도입 전 다음 항목을 반드시 확인해야 한다.
| 체크 항목 | 설명 |
|---|---|
| RTO | 장애 발생 후 얼마 안에 복구되어야 하는가 |
| RPO | 장애 시 데이터 유실을 어느 정도까지 허용할 수 있는가 |
| 읽기/쓰기 비율 | Slave read scale-out이 필요한가 |
| replication lag 허용 범위 | 지연된 데이터를 읽어도 되는가 |
| 자동 Failover 허용 여부 | 자동 전환이 더 위험한 환경은 아닌가 |
| split-brain 방지 | 두 Master가 동시에 write하지 않도록 보장되는가 |
| 애플리케이션 재연결 | DB 장애 시 connection pool이 정상적으로 reconnect하는가 |
| 트랜잭션 재시도 | Failover 중 실패한 write를 재시도할 수 있는가 |
| 모니터링 | replication lag, read-only, VIP 위치, primary 상태를 감시하는가 |
| 복구 절차 | 장애 복구된 기존 Master를 어떻게 재편입할 것인가 |
특히 애플리케이션 관점에서는 connection pool 설정도 중요하다.
DB Failover가 정상적으로 끝났더라도 애플리케이션이 기존 죽은 커넥션을 계속 잡고 있으면 서비스 장애가 길어질 수 있다.
따라서 HikariCP 같은 커넥션 풀에서는 다음 항목을 함께 점검해야 한다.
connectionTimeout
validationTimeout
maxLifetime
idleTimeout
keepaliveTime
connectionTestQuery 또는 JDBC driver validationDB HA는 DB만의 문제가 아니라 애플리케이션, 네트워크, 커넥션 풀, 모니터링까지 함께 설계해야 한다.
18. 결론
DB 이중화의 목적은 단순히 DB 서버를 2대 두는 것이 아니다.
장애 발생 시 서비스 중단 시간을 줄이고, 데이터 유실 가능성을 낮추며, 운영자가 예측 가능한 방식으로 복구할 수 있도록 만드는 것이다.
정리하면 다음과 같다.
단일 DB
-> 장애 시 복구 완료까지 서비스 중단
DB 2대 수동 전환
-> 장애 시 운영자가 접속 대상 변경
VIP 기반 구성
-> 애플리케이션 접속 정보 변경 없이 DB 전환 가능
Replication + Failover 자동화
-> 장애 감지, 승격, VIP 전환, 복제 재구성 자동화
Group Replication / InnoDB Cluster
-> MySQL 자체 클러스터 기반 HA 구성
Managed DB
-> 클라우드 제공 HA 기능 활용각 방식의 선택 기준은 다음과 같이 볼 수 있다.
기존 온프레미스 MySQL
-> MHA + Semi-sync + VIP
신규 MySQL HA 구성
-> InnoDB Cluster + MySQL Router
클라우드 운영
-> Aurora, RDS, Cloud SQL 같은 Managed DB
MMM
-> 신규 도입 비추천DB 이중화에서 가장 중요한 것은 “자동 Failover가 되는가”보다 “정합성을 지키면서 안전하게 Failover가 되는가”이다.
빠른 장애 전환만 보고 구성하면 split-brain, 데이터 유실, 복제 충돌 같은 더 큰 문제가 발생할 수 있다.
따라서 DB 이중화는 다음 순서로 접근하는 것이 좋다.
1. 장애 허용 시간(RTO) 정의
2. 데이터 유실 허용 범위(RPO) 정의
3. 복제 방식 선택
4. Failover 방식 선택
5. VIP 또는 Proxy 라우팅 구성
6. 애플리케이션 reconnect/retry 검증
7. 장애 복구 후 재편입 절차 문서화
8. 실제 장애 시나리오 테스트DB 이중화는 구축보다 검증이 더 중요하다.
문서상으로는 완벽한 HA 구조처럼 보여도, 실제 장애 상황에서 connection pool이 재연결하지 못하거나, VIP 전환이 늦거나, replication lag가 커져 있으면 서비스 장애는 그대로 발생한다.
결국 좋은 DB 이중화 구조란 특정 솔루션 이름으로 결정되는 것이 아니라, 장애 상황에서도 데이터 정합성과 서비스 복구 흐름이 예측 가능하게 동작하는 구조다.
'나의 주니어 개발 일기 > DB' 카테고리의 다른 글
| DB는 장애가 발생해도 어떻게 데이터를 복구할까? Redo와 Undo의 원리 (0) | 2026.07.23 |
|---|---|
| Supabase 도커(Docker)로 로컬 개발 환경 구축하기 (0) | 2026.02.02 |
| 샤딩과 파티셔닝, 무엇이 다르고 언제 써야 할까? (1) | 2025.08.29 |
| 커버링 인덱스, 클러스터드 인덱스, 넌클러스터드 인덱스 (1) | 2024.07.26 |
| DB Replication 해보기 (master-slave) by 도커 컴포즈 (2) | 2024.05.17 |

