쿠버네티스
서비스의 격리를 Docker로 했지만, 엄청 많은 서비스들을 일일이 배포하고 운영하는 역할이 필요하게 되면서 쿠버네티스가 등장하였다.


- 쿠버네티스 클러스터를 운영하는 운영자(Admin)
- 자신의 서비스를 배포하려는 사용자(User)
Overview
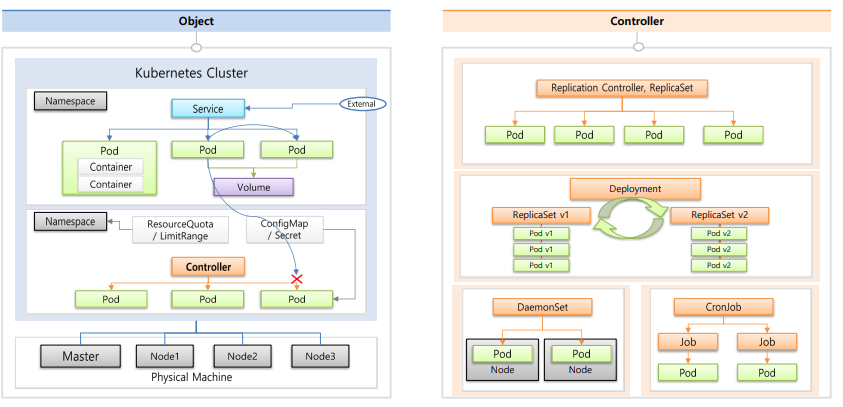
namespace
- 쿠버네티스 객체들을 독립된 공간으로 분리
Pod
- 쿠버네티스의 배포 최소 단위
Service
- Pod 들을 외부와 연결시켜줌
ResourceQuota/LimitRange
- namespace에서 사용할 수 있는 자원의 양을 한정(pod의 개수, cpu, memory 제한등..)
ConfigMap / Secret
- Pod의 환경변수
Replication Controller, ReplicaSet
- Pod 헬스체크 및 되살리기, Pod scale in out
Pod

파일 읽기를 예로 들어보면 cpu공유시에 여러 파일을 동시에 읽는다고 파일 읽는 속도가 느려질뿐 시스템이 종료되지는 않는다(cpu)
그러나 메모리 공유시에는 잘못된 메모리가 참조되었습니다 라고 하면서 시스템이 종료된다.
이런 특성으로 cpu 초과시에는 Pod가 종료되지 않지만 메모리 초과시 Pod가 종료된다.
Service
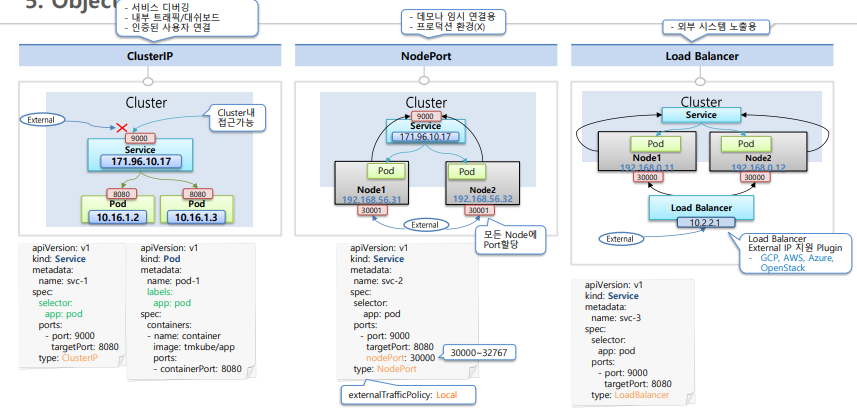
ClusterIP
- ClusterIp는 클러스터 내에서만 유효한 IP 이다
- Pod의 아이피는 Pod가 on/off 할때마다 변하지만 Service는 변하지 않는다.
- 그래서 Pod는 항상 Service로부터 접근해야한다.
- 주 사용처: 인가된 사용자, 내부 대시보드, Pod의 서비스 상태 디버깅
NodePort
NodePort가 열리는 위치
[Client]
↓
<Node IP>:30080 ← 여기!
↓
kube-proxy (iptables/ipvs)
↓
Service (ClusterIP)
↓
Pod그래서 ip도 호스트의 ip에 포트를 연다.
- 모든 노드에 같은 포트 할당 가능
- 1번 노드에서 온 데이터라도 2번 노드로 전송 가능
- externalTrafficPolicy: Local 옵션을 적용하면 특정 노드 포트의 ip로 접근하는 트래픽은 service가 해당 노드위에 올려져있는 Pod에게만 데이터를 전달한다.
- 주 사용처: 내부망 연결, 데모나 임시 연결용, 내부 환경에서 시스템 개발을 하다가 외부의 간단한 데모를 보여줄때 종종 네트워크 중계기에 포트포워딩을 해서 외부에서 내부시스템에 연결할때, 이럴때 NodePort를 잠시 뚫어두고 사용한다.
Load Balancer
주 사용처: 외부 시스템 노출용도
Load Balancer 타입으로 만들면 따로 별도의 외부접속 ip 플러그인이 설치되어 있어야만 Ip가 자동으로 할당된다.(ex. GCP, AWS..)
Kubernetes:
“LoadBalancer가 필요하군요. 누군가 외부 LB 만들어 주세요 🙏”
실제 LB 생성 & IP 할당:
👉 클라우드 제공자(GCP, AWS, Azure 등) 또는 LB 컨트롤러가 담당
폐쇠망에서는?
1️⃣ LoadBalancer 타입 생성은 가능
$ kubectl expose deployment my-app \
--type=LoadBalancer \
--port=80하지만 상태를 보면:
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
my-app LoadBalancer 10.96.12.34 <pending> 80:31234/TCP👉 EXTERNAL-IP가 <pending>에서 절대 안 바뀜
왜냐면: 외부 IP를 할당해 줄 LB 컨트롤러가 없기 때문
로컬 / 폐쇄망에서의 현실적인 대안
Ingress + Ingress Controller
- NGINX Ingress Controller
- Traefik
- HAProxy
구성 예시
[Client]
↓ 80/443
[Ingress Controller Service] (NodePort or LoadBalancer)
↓
[Ingress Controller Pod] ← NGINX 실행 중
↓ (Ingress 규칙 적용)
[Service (ClusterIP)]
↓
[Pod]👉 Ingress Controller = 실제 HTTP 서버 (NGINX)
👉 Ingress = 그 서버에 먹이는 라우팅 설정
Controller Pod (Deployment)
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app: ingress-nginx
template:
metadata:
labels:
app: ingress-nginx
spec:
containers:
- name: controller
image: registry.k8s.io/ingress-nginx/controller:v1.9.5
args:
- /nginx-ingress-controller
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443✔️ 이 Pod 안에서 NGINX가 실행 중
✔️ Ingress 리소스를 감시(watch)함
Controller Service (외부 노출)
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx
namespace: ingress-nginx
spec:
type: NodePort # 로컬/폐쇄망에서는 보통 NodePort
selector:
app: ingress-nginx
ports:
- name: http
port: 80
nodePort: 30080
- name: https
port: 443
nodePort: 30443(클라우드면 type: LoadBalancer로 바뀜)
Ingress 리소스 (라우팅 규칙)
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: app-ingress
spec:
rules:
- host: app.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend
port:
number: 80👉 app.local로 오면 frontend Service로 전달
궁금증: nginx 설정 파일이 어디에도 마운트 되지 않았는데 어떻게 로드밸런싱을 해주지?
Pod가 여러 개면, Ingress Controller(NGINX)가 Service 뒤에 있는 Pod들로 자동 로드밸런싱을 한다.
| 레벨 | 역할 |
|---|---|
| Ingress Controller (NGINX) | L7 로드밸런싱 (HTTP) |
| Service (kube-proxy) | L4 로드밸런싱 (TCP) |
| Pod | 실제 처리 |
Volume
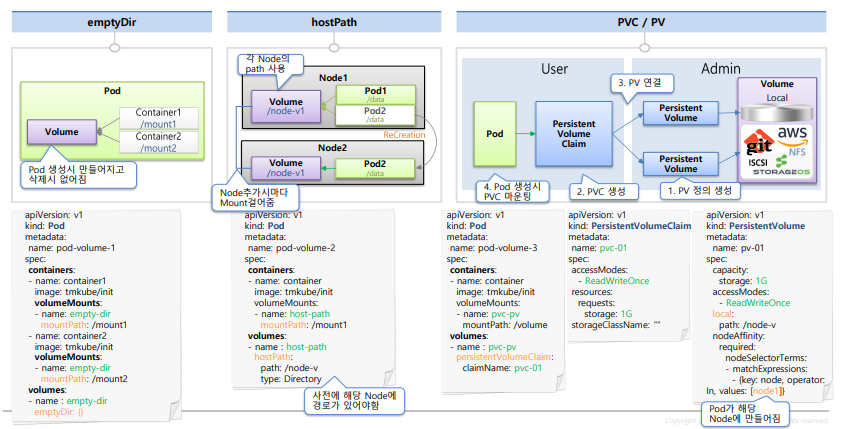
emptyDir
- 컨테이너들 끼리 볼륨을 공유하기 위한 목적
- Pod 안에서 생성되기 때문에 일시적인 사용목적에 의한 데이터 용도로만 사용되어야 한다
- Pod가 죽으면 emptyDIr 볼륨의 데이터로 사라진다
apiVersion: v1
kind: Pod
metadata:
name: pod-volume-1
spec:
containers:
- name: container1
image: kubetm/init
volumeMounts:
- name: empty-dir
mountPath: /mount1
- name: container2
image: kubetm/init
volumeMounts:
- name: empty-dir
mountPath: /mount2
volumes:
- name : empty-dir
emptyDir: {}hostPath
- Pod들이 개별적으로 path를 공유하기 때문에 Pod가 죽어도 데이터가 사라지지 않는다.
- 만약 Pod2가 죽고 되살아났을때 기존 Node1에서 Node2로 재생성되었다면 Pod2는 기존 Node1의 path를 자동으로 읽지 못한다.
- 때문에 노드가 추가될때마다 리눅스 시스템 별도의 마운트 기술을 이용하여 Node2에도 자동으로 구성해주어야 한다. 이것은 쿠버네티스가 자동으로 해주는것이 아닌 직접 사람이 개입해줘야 함으로 권장되지는 않는 방법이다.
- 참고로 hostPath 정보는 Pod가 만들어지기 전에 미리 만들어져있어야 한다.
아래와 같이 생성해두고, 다음 새로운 Pod를 만들때 노드선언부를 제외하고 만들게되면 새로운 노드가 만들어지게 되면서
기존 노드에 생성되어 있던 hostPath의 설정값은 새로운 Pod에서는 존재하지 않게 된다.
apiVersion: v1
kind: Pod
metadata:
name: pod-volume-3
###### 노드선언 ######
spec:
nodeSelector:
kubernetes.io/hostname: k8s-worker1
#####################
containers:
- name: container
image: kubetm/init
volumeMounts:
- name: host-path
mountPath: /mount1
volumes:
- name : host-path
hostPath:
path: /node-v
type: DirectoryOrCreatePVC/PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-01
spec:
capacity:
storage: 1G
accessModes:
- ReadWriteOnce
local:
path: /node-v
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- {key: kubernetes.io/hostname, operator: In, values: [k8s-worker1]} values: [k8s-worker1]} 만 주의깊게 확인하면 된다. worker1에 저장된다는 의미다
'나의 주니어 개발 일기 > 쿠버네티스' 카테고리의 다른 글
| 쿠버네티스 정리2 (0) | 2026.03.23 |
|---|---|
| [K8s] 쿠버네티스 사설 레지스트리 구축 및 x509: certificate signed by unknown authority 에러 해결 가이드 (0) | 2026.03.06 |
| 쿠버네티스 환경세팅시 Could not find a version that satisfies the requirement ansible==8.5.0 오류 발생 (0) | 2024.03.08 |
